 |
Towards Distributed Immersive Tele-presence – Dynamic Human Shape and Environment Modelling (Jie Chen et al.)
The spread of COVID-19 significantly limited our daily activity and changed the way we live, work, and communicate with each other. During this difficult time, virtual modes of working and communication become necessities for most challenging working situations. In this project, we will focus on tackling some of the key challenges of virtual tele-presence: capturing and animating human centric models and the environment for efficient modes of virtual communications.
3D Human capture commonly aims to truthfully reconstruct 3D human models with detailed body appearance and motion. High-end volumetric human shape capture systems based on dense camera rigs and custom-designed lighting conditions can achieve high-quality reconstruction, but they require expensive hardware investments and professional studio set-ups. Recently, there emerged new techniques of using limited RGBD cameras for volumetric capture of human shapes and motion, which drastically reduced the hardware cost and achieve satisfactory reconstruction quality. However, these solutions still require a centralized set up, and are usually designed for single target modelling. When we want to model complex social scenarios such as multi-person interactions, the limited sensor resources for a centralized system will limit the final rendering quality for each individual target. With the popularization of personal imaging devices such as cellphone cameras, iPad, go-pro cameras etc., these handy devices can capture highly detailed local features and collaboratively contribute to the global model. This motivates our ambition to utilize distributed personal capture devices to fuse details that belong to individual targets to the central stage, and progressively improve the content details. In this proposed study, we will work on three promising directions which are critical to realize such a distributed human shape capture system.
In the first task, we will work on a distributed 3D human shape and motion modeling mechanism via latent deformation encoding and surface intrinsic property regularization. The pipeline takes the monocular video stream as input and can model the dynamic deformations of the human surface vividly based on different distributed imaging modalities during test time. In the second task, we plan to investigate a novel and effective deep-learning based framework to computationally reconstruct high-fidelity dynamic 3D point clouds with high spatial and high temporal resolutions, based on distributed, low-cost dynamic sparse and static dense point cloud captures. In the third task, we will investigate the challenge of scene geometry estimation based on measurements from various imaging modalities (e.g., multi heterogeneous camera arrays, light field cameras, RGBD cameras, etc.), and various capture modes (scanning, videotaping, etc.). Domain-invariant features and various self-supervised/unsupervised learning mechanisms will be investigated for consistent inference.
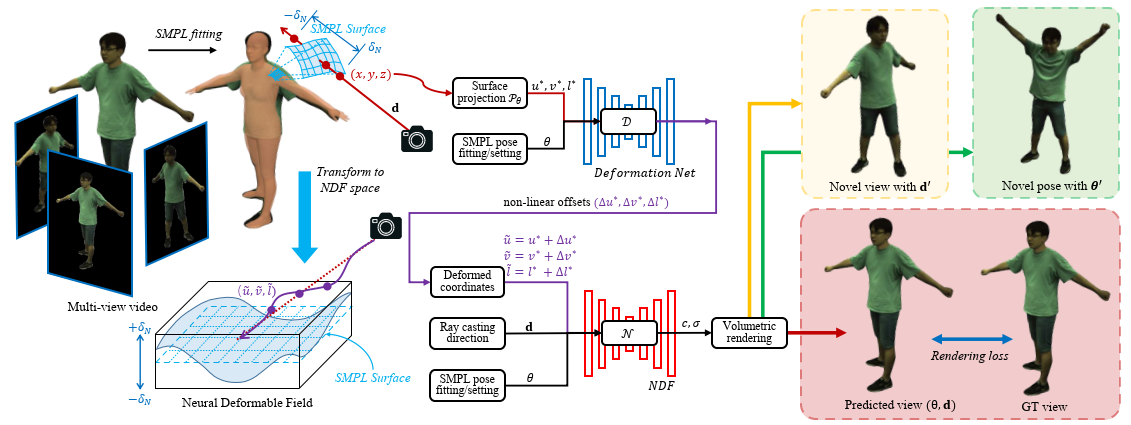
The below figure shows one of our existing work that reconstruct a dynamic human body based on a sparse set of RGB camera views.
References:
- Ruiqi Zhang, Jie Chen, “NDF: Neural Deformable Fields for Dynamic Human Modelling,” in Proceedings of European Conference on Computer Vision, pp. 37-52, 2022
- Wenpeng Xing, Jie Chen, Zaifeng Yang, Qiang Wang, and Yike Guo, “Scale-Consistent Fusion: from Heterogeneous Local Sampling to Global Immersive Rendering,” IEEE Transactions on Image Processing, vol. 31, pp. 6109-6123, 2022
For further information on this research topic, please contact Prof. Jie Chen.
|
|